
Look, I Get It—AI Infrastructure Sounds Boring
You clicked on this expecting another dry tech article filled with acronyms that make your eyes glaze over faster than a Monday morning meeting. But here’s the thing: AMD scalable AI infrastructure is actually the secret sauce behind every ChatGPT conversation, every AI-generated image that’s gone viral, and every recommendation algorithm that somehow knows you need new sneakers before you do.
And honestly? It’s kind of wild.
I’ve spent way too many late nights tinkering with AI models (don’t judge), and I can tell you that the infrastructure powering these systems is where the real magic happens. It’s like comparing a souped-up street racer to a go-kart—sure, they both have wheels, but one’s built for actual speed.
So let’s talk about AMD’s latest play in the AI game. Because if you’re trying to build something in AI—whether it’s a side hustle app, a tech startup, or just understand what’s happening in the data centers powering our digital lives—you need to know about this.
What is AMD Scalable AI Infrastructure and Why Should You Actually Care?
Here’s the straightforward answer: AMD scalable AI infrastructure is AMD’s complete ecosystem of hardware and software designed to handle massive AI workloads. Think of it as the ultimate gaming rig, but instead of running Cyberpunk 2077, it’s training AI models that can write code, generate videos, or predict stock trends.
The “scalable” part is key. You know how your phone slows down when you have 47 Chrome tabs open? Now imagine you’re trying to train an AI model with billions of parameters across thousands of GPUs. Without proper scalability, the whole thing crashes harder than my attempt at sourdough during lockdown.
AMD’s approach combines three critical elements:
- Beefy processors that don’t choke under pressure
- Smart networking that lets all these components talk to each other at lightning speed
- Open standards that play nice with everyone (revolutionary, I know)
The importance? Companies are spending billions on AI infrastructure. According to industry trends, AI workload demands are doubling every few months. If your infrastructure can’t scale, you’re basically showing up to a Formula 1 race with a bicycle.
The Helios AI Rack Platform: AMD’s Power Move
Okay, so AMD’s “Helios” AI rack platform sounds like something from a sci-fi movie, and honestly, it kind of is. This is AMD’s fully integrated, rack-scale solution that bundles everything you need for AI computing into one cohesive system.

Picture this: Instead of buying separate components from different vendors and spending weeks (or months) making them work together, Helios gives you a plug-and-play AI supercomputer. It’s like buying a pre-built gaming PC instead of sourcing parts from five different websites and praying they’re compatible.
Here’s how Helios enables scalability:
1. Unified Architecture
Everything’s designed to work together from the ground up. No more compatibility nightmares or bottlenecks because your GPUs and CPUs are having communication issues.
2. Open Standard Interconnects
Using UALink (more on this later), Helios can scale from a few GPUs to thousands without breaking a sweat. It’s the difference between a group chat and a stadium full of people all talking at once—except everyone can still hear each other perfectly.
3. Flexible Configuration
Need more compute power? Add another rack. Need more networking bandwidth? Upgrade the NICs. It’s modular, which means you’re not locked into one configuration forever.
The platform integrates AMD Instinct GPUs, EPYC CPUs, and Pensando networking into a single, coherent system. For data centers and cloud providers, this is huge. It’s like going from managing a thousand separate moving parts to controlling a well-oiled machine.
AMD Instinct MI400 GPUs: The Heavy Hitters
Let’s talk about the star players: AMD Instinct MI400 GPUs. These are the workhorses that actually crunch the numbers when you’re training or running AI models.
The specs are honestly insane:
| Specification | MI400 Series |
|---|---|
| HBM Memory | Up to 432GB HBM4 |
| Performance | 40 PFLOPS FP4 |
| Use Case | Rack-scale AI training & inference |
| Architecture | Next-generation CDNA |
432GB of HBM4 memory. To put that in perspective, most gaming GPUs have 8-24GB. This is like comparing a kiddie pool to the Pacific Ocean. When you’re working with large language models or multi-modal AI systems, you need that much memory to keep all the model parameters loaded without constantly shuffling data around.
The 40 PFLOPS (petaflops) of FP4 performance means these GPUs can perform 40 quadrillion floating-point operations per second. My brain can barely comprehend that number, let alone match it.
But here’s what really matters for scalability: The MI400 series is designed from the ground up to work in massive clusters. You can connect hundreds or thousands of these GPUs, and they’ll distribute workloads efficiently without creating bottlenecks. It’s like having a massive team where everyone knows their role and executes flawlessly.
Real-World Impact
For agentic AI—those autonomous AI systems that can perform complex tasks without constant human oversight—you need GPUs that can handle multiple concurrent operations. The MI400 handles this by offering:
- High memory bandwidth for rapid data access
- Efficient power consumption (because your electricity bill matters)
- Advanced cooling considerations for dense rack deployments
Companies training the next generation of AI models aren’t using one or two GPUs. They’re using thousands. The MI400’s architecture makes that economically feasible and technically practical.

AMD EPYC “Venice” CPUs: The Unsung Heroes
Everyone obsesses over GPUs, but here’s a hot take: AMD EPYC “Venice” CPUs are just as critical to scalable AI infrastructure. GPUs might be the sports cars of compute, but CPUs are the logistics network that keeps everything running smoothly.
The 6th generation EPYC Venice processors are packing some serious heat:
- Up to 256 Zen 6 cores (yes, you read that right)
- 1.7x performance gains over previous generations
- 1.6 TB/s memory bandwidth for feeding those hungry GPUs
Think about what happens in an AI workflow. You’ve got:
- Data preprocessing (that’s CPU territory)
- Model loading and initialization (CPU again)
- Coordinating GPU workloads (still the CPU)
- Handling I/O operations (you guessed it)
- Managing system resources (all CPU, baby)
Without powerful CPUs, your expensive GPUs end up sitting idle, waiting for data like a sports car stuck in rush hour traffic. Venice CPUs eliminate these bottlenecks.
Why This Matters for Scale
When you’re running AI at scale, you’re dealing with:
- Massive datasets being loaded into memory
- Complex orchestration across hundreds of compute nodes
- Real-time adjustments to workload distribution
- Continuous monitoring of system health
The 256-core configuration means you can dedicate specific cores to specific tasks without degradation. Some cores handle networking, others manage storage I/O, and others coordinate GPU operations. It’s like having a well-organized kitchen brigade instead of one overwhelmed chef.
The 1.6 TB/s memory bandwidth is particularly crucial. AI models need constant access to parameters, training data, and intermediate results. Slow memory access creates bottlenecks faster than a broken-down car on a single-lane highway.
UALink™: The Secret Interconnect Nobody’s Talking About
Alright, here’s where things get interesting. UALink™ might sound like just another tech acronym, but it’s actually a game-changer for GPU interconnection in AMD AI racks.
Imagine you’ve got a dozen people trying to work on the same project. If they’re all sending emails back and forth, progress is slow. But if they’re in the same room with a whiteboard, collaboration is instantaneous. That’s essentially what UALink does for GPUs.
What Makes UALink Special?
Open Standard Architecture
Unlike proprietary interconnects (looking at you, NVLink), UALink is an open standard. This means:
- Multiple vendors can support it
- You’re not locked into one ecosystem
- Innovation happens faster because everyone can contribute
- Costs come down over time
High-Bandwidth, Low-Latency Communication
UALink enables direct GPU-to-GPU communication without bottlenecking through the CPU or traditional PCIe lanes. When you’re training massive models, every millisecond of latency matters.
Scalable Architecture
Here’s the beautiful part: UALink supports scaling from 2 GPUs to thousands. The same interconnect technology that works in a small server works in a massive data center deployment.
The Technical Breakdown
| Feature | Benefit |
|---|---|
| Bandwidth | Multi-terabyte/sec aggregate throughput |
| Topology | Flexible mesh and tree configurations |
| Latency | Sub-microsecond GPU-to-GPU communication |
| Scalability | Supports massive GPU clusters |
For AMD AI compute scalability, UALink solves one of the biggest challenges: keeping all those GPUs fed with data and coordinated. Traditional approaches create bottlenecks when you scale beyond a few dozen GPUs. UALink maintains performance even with hundreds or thousands of GPUs working in concert.
Think of it like upgrading from a two-lane country road to a 12-lane superhighway. The destination is the same, but the traffic capacity is exponentially higher.
AMD Pensando “Vulcano” AI NICs: Speed Demons of Data Transfer
Let’s talk about AMD Pensando “Vulcano” AI NICs (Network Interface Cards), because these bad boys are doing the heavy lifting when it comes to moving data around your AI infrastructure.
800G throughput and 8x improved scale-out bandwidth. If those numbers don’t make you sit up and take notice, let me put it in perspective:
That’s enough bandwidth to transfer the entire Netflix library in about 30 seconds. Or download every song ever recorded in a few minutes. For AI workloads, it means:
- Training data flows seamlessly to compute nodes
- Model checkpoints save without interrupting training
- Distributed inference happens in real-time
- Multi-node collaboration occurs without latency issues
Why NICs Matter for AI
Here’s something most people don’t realize: In modern AI infrastructure, the network is often the bottleneck. You can have the fastest GPUs and CPUs in the world, but if data can’t move between them efficiently, you’re wasting money and time.
Vulcano AI NICs address this by:
1. Intelligent Traffic Management
These aren’t just dumb pipes pushing data. They include smart routing and prioritization to ensure critical AI workloads get bandwidth when needed.
2. Hardware Acceleration
Network protocol processing happens on the NIC itself, freeing up CPU cycles for actual compute work.
3. Security Features
Built-in encryption and security don’t compromise performance—crucial when you’re dealing with sensitive training data or proprietary models.
4. Scalability
The 8x improvement in scale-out bandwidth means you can add more nodes to your AI cluster without creating a traffic jam. It’s like adding more on-ramps to that superhighway we talked about.
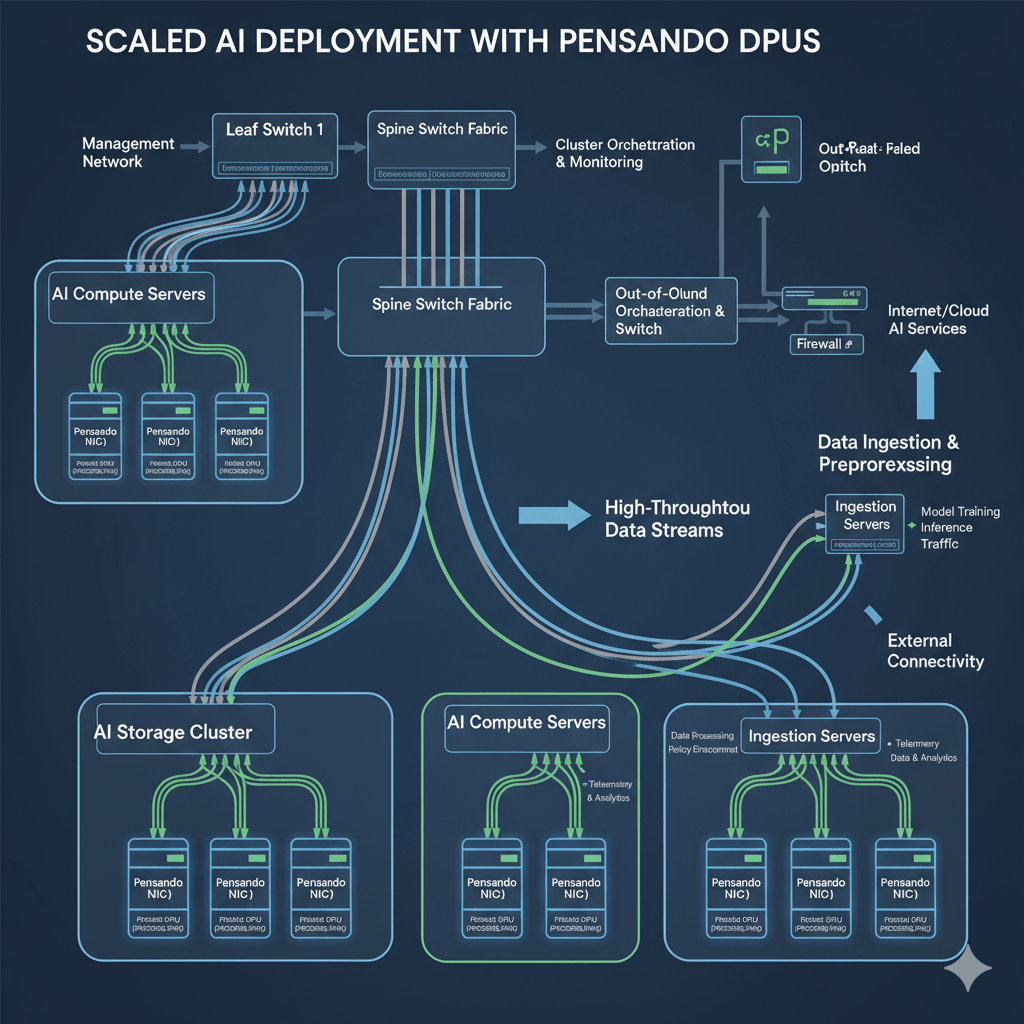
For industries running AMD AI data center solutions, network performance directly translates to ROI. Faster data movement means:
- Shorter training times
- Lower infrastructure costs
- Better GPU utilization
- Faster time-to-market for AI products
Industries Crushing It with AMD’s Scalable AI Infrastructure
So who’s actually using this stuff? Turns out, AMD’s scalable AI infrastructure solutions are making waves across multiple sectors. Let me break down the heavy hitters:
1. Healthcare and Pharmaceuticals
Drug discovery is insanely compute-intensive. Simulating molecular interactions, analyzing patient data, and training diagnostic AI models require massive computational resources. AMD’s infrastructure enables:
- Faster drug discovery cycles
- Real-time medical imaging analysis
- Personalized treatment recommendations
- Genomic sequence analysis at scale
Companies are cutting years off research timelines by running thousands of simultaneous simulations on AMD hardware.
2. Financial Services
Wall Street runs on data and milliseconds matter. AMD AI infrastructure performance metrics show significant advantages for:
- Real-time fraud detection
- Algorithmic trading
- Risk assessment modeling
- Customer behavior prediction
Banks and hedge funds are deploying AMD-powered AI to process billions of transactions and market signals simultaneously.
3. Entertainment and Media
Ever wonder how Netflix knows what you’ll binge next? Or how studios are using AI to enhance visual effects? That’s AMD infrastructure at work:
- Content recommendation engines
- Video rendering and enhancement
- Music generation and production
- Game development and testing
4. Cloud Service Providers
AWS, Azure, Google Cloud—the major cloud providers are integrating AMD AI data center solutions to offer scalable AI services to customers. This means:
- More affordable AI training options
- Flexible on-demand compute resources
- Geographic distribution of AI workloads
- Energy-efficient data center operations
5. Autonomous Vehicles
Self-driving cars need to process sensor data, make decisions, and predict scenarios in real-time. AMD’s infrastructure powers:
- Simulation environments for training
- Real-time inference at the edge
- Fleet learning across vehicles
- Safety validation testing
6. Research and Academia
Universities and research institutions leverage AMD hardware for:
- Climate modeling and weather prediction
- Physics simulations
- Astronomy data processing
- Materials science research
The scalability means researchers can tackle problems that were computationally impossible just a few years ago.
TechWorkers #SideHustlers #AIEnthusiasts #Developers #DataScience #MachineLearning #TechStartups #AIInfrastructure #TechEducation #FutureTech